
Daniel Schwertführer
CEO
You can hold me accountable if your requirements are not met.
Process diverse sources of information efficiently.
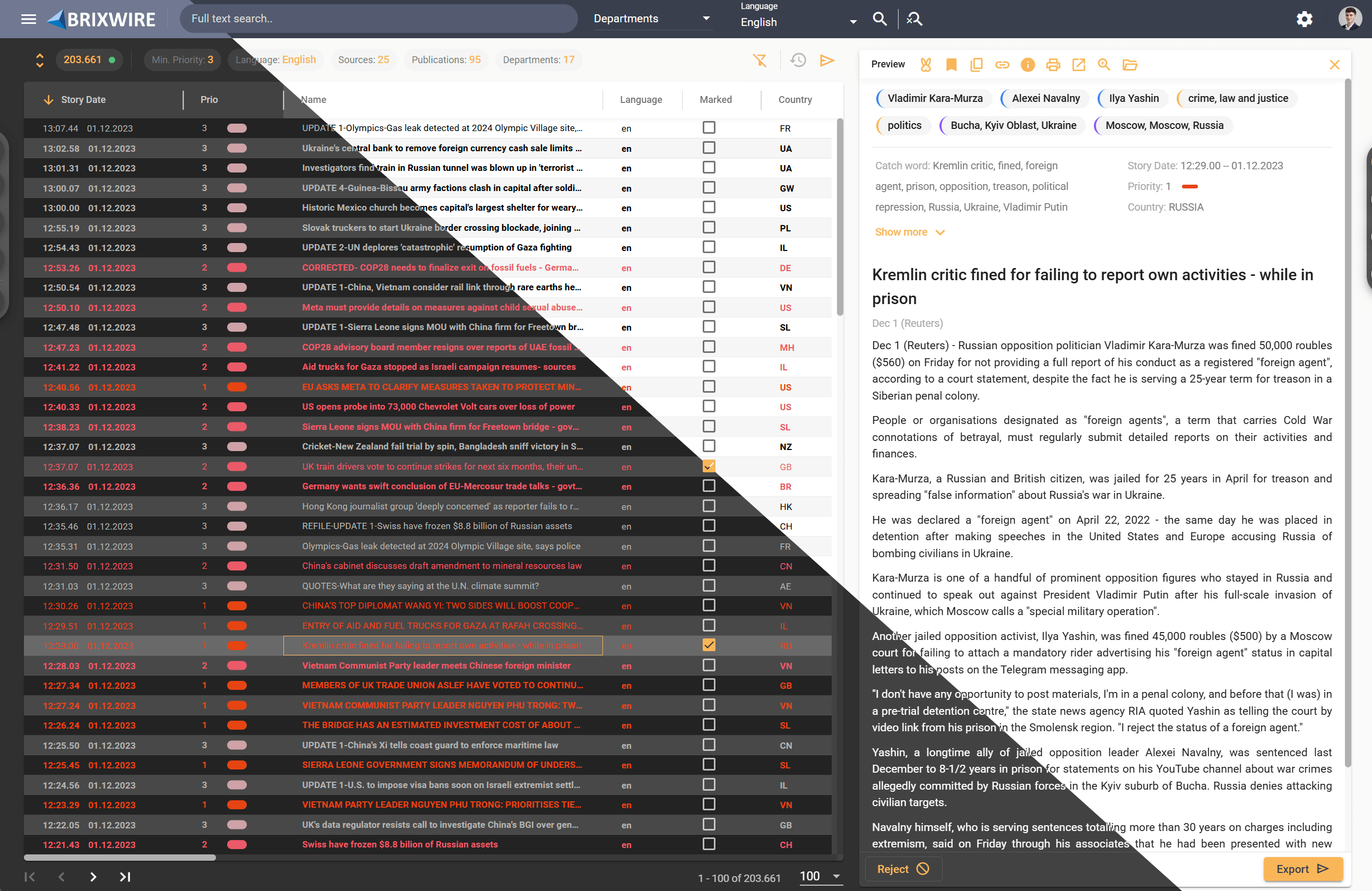
Editors must gather content from many separate sources such as emails, feeds, internal systems, social media and external websites. This manual work is time consuming and risks missing important material.
Content management systems may integrate sources but cannot process large volumes from diverse inputs efficiently. They lack advanced search and filtering at scale. Editors must work through extensive data without tools to refine by relevance, topic, provider or format.
Such systems support few formats and protocols. Their main role is managing prepared content, not aggregating or normalizing external input. Editorial teams receive much irrelevant or duplicate content, which delays decisions and lowers efficiency.
Relying only on standard sources limits editorial scope. Editors and journalists face restrictions in coverage, which reduces creativity and differentiation.
Using the same feeds as competitors creates duplicate content. This weakens editorial voice and reduces audience appeal.
Without scalable ways to manage diverse inputs, editorial growth remains limited by the range of available sources.
Manual tasks such as copying, pasting and repetitive navigation reduce productivity. Small actions add up to major time loss in daily work.
Searching, tagging and routing are especially slow. Editors must review items, assign categories and choose destinations from incomplete data. Under deadlines, these steps cause delays, errors and bottlenecks.
Without automation, editorial resources are consumed by procedure instead of quality and timely publishing. Efficiency and output decline, especially with continuous multi platform demands.
Disconnected editorial and content systems create inefficiencies. Without a unified workflow, teams repeat tasks across platforms, increasing errors and inconsistencies.
Content appears in different versions and formats. Editors spend time fixing metadata, formatting and conflicting updates. This fragmentation causes discrepancies between digital and print, which weakens consistency.
Without a central pipeline, data accuracy suffers. Source details, status and version history may be lost or altered. Editors must correct issues manually, which consumes resources and limits output.
Changes in input sources require modifications across platforms. Without central control, outages are frequent.
In many publishing environments, source integration is secondary. Editorial and content management systems provide basic integrations, not core functions. These are neither scalable nor adaptable to new formats or channels.
When formats, protocols or upstream systems change, these integrations break. Each adjustment demands new configurations, causing repeated effort and interruptions. Traditional publishing solutions cannot adapt quickly, leaving newsrooms exposed to delays and instability.
Content Management Systems are built to structure and display finalized content. They are not designed to aggregate, filter, or manage large volumes of raw data from varied sources. Features such as advanced filtering, cross‑source search, flexible format handling, and high speed processing are typically missing or limited. Direct integration of sources into a CMS is a weak workaround, not a viable solution.
Modern newsrooms depend on systems that can process high volume, diverse content streams efficiently. Traditional CMS platforms cannot meet these demands. Editors are left to navigate excessive, irrelevant data without the necessary tools for speed, scale, or precision. The result is reduced productivity and operational friction.
Customizing a CMS to support direct sourcing is expensive, time intensive, and rarely sufficient. Even heavy investment yields only partial functionality. Additional infrastructure is required for multi‑channel publishing, increasing both complexity and cost. With thousands of CMS options and frequent platform changes, each transition restarts the entire integration effort, locking teams in a cycle of inefficiency.
BrixWire is a news aggregation and editorial workflow platform for publishers, newsrooms, and media organizations. It centralizes content sourcing from multiple formats, enriches metadata, and distributes stories efficiently across digital and print channels.
BrixWire NewsHub is engineered specifically for large scale content aggregation. It supports multiple sources like agency feeds, web scraping, RSS, social media, mail, internal systems and office formats with ease. Built‑in tools for filtering, deduplication, search, and metadata management ensure that only relevant, high quality content reaches editorial teams quickly and reliably.
BrixWire decouples sourcing from publishing infrastructure. You gain full control over aggregation workflows, regardless of CMS or print platform. This flexibility eliminates costly rework and safeguards long term operational efficiency.
Sourcing becomes centralized, consistent, and scalable. Integration overhead is eliminated, editorial output is streamlined, and your newsroom remains agile amid evolving technologies. BrixWire is the foundation for efficient, future ready content operations.
One workspace for sourcing, enrichment, and editorial decisions. Enabling faster access to the right information from all sources.
Automations relieve editorial staff from routine tasks while maintaining full control over content decisions.
Gain access to previously unstructured regional content and strengthen your local footprint.
Write anywhere with full synchronization across CMS, print, and legacy systems.
Enhance editorial output and depth through access to automatically translated foreign content.
React quickly to breaking news through faster detection and streamlined publishing. Reduce response time with efficient content workflows.
Manage large volumes of content with high performance. Reuse and distribute stories efficiently across all platforms.
Achieve scalability through a robust and adaptable content infrastructure.
























BrixWire impresses our teams at Tamedia with its user friendliness, stability, and the
flexibility to implement new ideas quickly.
BrixWire has proven to be a scalable solution for us, handling more than 600 sources and meeting
the
growing content requirements of over 20 digital and print titles.
At the same time, we value the close partnership with BrixWare, characterized by quick
responses,
strong process alignment, and a trustful collaboration.

BrixWire is a technically robust solution that convinces
with its stability and modern user interface.
The adaptability of the software enables easy
integration
into existing system landscapes.
With BrixWire we have found a solution that fits seamlessly
into
our
infrastructure and can also be adapted according to our users’ wishes.
The transformation engine enables conversion between all formats, allowing seamless integration of any source. It also makes previously vendor-locked content from CMSs, editorial systems, and other platforms accessible across the workflow. This ensures full interoperability and consistent content availability.
Each workflow may combine multiple operations, integrating human tasks with AI powered steps to ensure quality control. They are provider independent, transparent, and support various AI models, including self hosted options, offering flexibility in quality, cost, and efficiency. BrixWire connects to all systems, serving as a unified platform for managing AI driven workflows throughout the editorial process.
BrixWire provides advanced scraping capabilities to extract and structure content from unstructured sources. This makes previously inaccessible information available for organization-wide use and further processing. It ensures that valuable content from websites can be integrated seamlessly into existing workflows.
A robust plugin architecture enables easy expansion and precise configuration. New sources, target systems, monitoring, authentication, AI, and other components can be seamlessly integrated and tailored to specific requirements. This allows operation either as a lightweight solution for a single use case or as the central backbone of newsroom infrastructure.
Comprehensive monitoring capabilities cover all critical components. Conventional system monitoring is supported through interfaces for leading providers, ensuring technical stability. Source monitoring verifies the complete availability of all connected sources to prevent information loss, while output monitoring ensures reliable delivery to all target systems.
BrixWire enables desk automation for recurring content such as traffic news, elections, and sports events. These topics can be automatically sourced, processed, and prepared in the publication's tone, either fully automated or pending manual approval. This ensures timely and consistent output with minimal editorial effort.
| Deployment | On premise or cloud; Linux, Windows & Docker Containers |
|---|---|
| Supported Agencies | AP, Bloomberg, AFP, APA, DPA, Reuters, ANSA, agi, ANP, KNA, epd, Keystone-SDA, swissinfo, STT, pap, EFE, colprensa, Agencia Brasil, ukrinform, agence europe, belga, PTI, UNI, ata, The Canadian Press, IRNA and many more |
| Social Media | X (Twitter), Telegram, Truth Social, Bluesky, Mastodon, LinkedIn |
| Formats | XML, JSON, NewsML, NewsML-G2, EventsML‑G2, SportsML‑G2, ANPA, RSS / Atom, HTML, XHTML, PDF, DOCX, Mail |
| Supported Systems | WordPress, Drupal, Typo3, PEIQ, contentful, Livingdocs, Purple, directus, PEIQ, WoodWing, InterRed, Atex, K4, Kordiam, Jira; Additional systems can be integrated |
| AI & Translation Providers | OpenAI, Anthropic, Gemini, AzureAI, DeepL & Self hosted models; Additional providers can be connected |
| Authentication | Integrated BrixWire System with Permissions, Roles & Groups. SAML 2.0, OIDC, LDAP. SSO with Okta, Entra ID, Google Workspace, Keycloak, Ping Identity |
| Monitoring | Metrics, logs, alerts, tracing. Integration for common dashboards like Grafana |
BrixWire is developed in close collaboration with newsrooms, reflecting practical industry needs.
With more than 25 years of experience in the publishing industry, we understand the challenges and have built BrixWire to address them.
We don't treat BrixWire as a rigid, finished product. It continuously evolves according to your specific requirements.
Direct communication is our standard; we do not hide behind tickets or impersonal support channels.
We take full responsibility for delivering outcomes that meet your expectations.
CEO
You can hold me accountable if your requirements are not met.

CIO
You can hold me accountable if performance or security is compromised

CPO
You can hold me accountable if your team does not enjoy using BrixWire.